
Pretty much all of the example applications of classification that I've seen given in textbooks and things like Coursera deal with data sets where the response variable of each instance is (or is at least assumed to be) independent of the response variable of every other instance. This is true for problems like spam classification or sentiment analysis of product reviews. This makes model selection via cross validation much easier (among other things). In this kind of problem it's common to see a variable setup like this:

Where  's are the explanatory variables,
's are the explanatory variables,  is the predicted response, and
is the predicted response, and 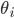 's are the fitted model weights.
's are the fitted model weights.
A lot of data in the world doesn't obey this convenient rule, though. Think of the problem of churn prediction at a phone company. In this case, it's convenient to measure both response and explanatory variables over fixed time intervals. For example, we might consider things like minutes used, MB of data used, overage charges and so forth as explanatory variables. For the response, we'd be interested in whether or not the client cancels their account during the following time interval. After all, it doesn't really do the company's sales staff any favors if the algorithm isn't giving them enough time to take preventive measures to save a client in danger of canceling. The model setup in this sort of example might look like this:

Notice that here we have a vector of lagged time series for each explanatory variable. In practice, it might be helpful to have longer vectors than what's been displayed for convenience here.
One issue that tends to crop up in problems like this is leakage. Leakage is an unwanted effect where information from the training set contaminates the test set and its known as one of the top 10 mistakes in data mining. This happens because somewhere there is an association between examples in the test set and examples in the training set and since we're dealing with time series data, our examples are by definition not independent.
What to do? In my experience, I've found that as long as the model setup follows the form given in the second equation above, things are generally ok. There are a couple of gotcha's I've found, however. One is the inclusion of variables that are constant over time. For example, in our phone company churn problem, we may believe that certain geographic markets are more stable than others and so we might want to include the latitude and longitude coordinates of our clients like so:

This may not always be a problem, but if we're using a nonlinear model that produces very tight local fits (like random forests, for example) then it's entirely possible that examples in the training set may correlate with the test set in a way that just wouldn't be possible when the model is being used in production. If the results in production are much less accurate than in the test set, it may be worth investigating the possibility of leakage.
Another case where leakage can occur is if we modify the time window over , for example, if we wanted to predict over the next 3 time intervals so that  becomes:
becomes:  . One might want to do this in order to mitigate noise in the response. This is usually fine during cross-validation as the main effect it has is to oversample the positive class. However, when testing on the holdout examples, one needs to make sure there is an adequate time offset between the two groups. For example, if we have time intervals of one day and a prediction interval of 3 days, then we would want to separate the training and holdout groups by at least 3 days.
. One might want to do this in order to mitigate noise in the response. This is usually fine during cross-validation as the main effect it has is to oversample the positive class. However, when testing on the holdout examples, one needs to make sure there is an adequate time offset between the two groups. For example, if we have time intervals of one day and a prediction interval of 3 days, then we would want to separate the training and holdout groups by at least 3 days.
Well, I hope this post has been helpful. Thank you for stopping by. I'm learning more all the time, so I'd be happy to hear any corrections or criticism in the comments. I've recently activated spam filtering in this blog, so hopefully they won't get lost!